Durante el Mobile World Congress en Barcelona, Mapillary (una aplicación de mapas generados por medio de crowdsourcing) se puso en contacto con el equipo de Firefox y se iniciaron las conversaciones para crear una versión para Firefox OS.
Peter Neubauer se acercó al equipo de Mozilla México para comentar la posibilidad de que desarrolladores mexicanos colaborasen en el repositorio de GitHub de esta aplicación con sede en Malmö, Suecia.
El propósito de este post es invitar a los desarrolladores que estén interesados en aprender más sobre la industria de computación visual a que vean el código que se tiene en el repositorio de Mapillary.
Si es algo que te llama la atención puedes enviar un correo electrónico a [email protected] con el asunto Firefox OS app mencionando que estás interesado en colaborar. Estarías trabajando en un proyecto global aportando a comunidades de Open Data.
Aprovechando este espacio también queremos anunciar que estamos formando parte del primer Meetup de Mapillary en América Latina que se realizará en la ciudad de Mérida (Yucatán).
Será una oportunidad para conocer al equipo de Mapillary y para que veas el potencial de esta aplicación que genera mapas visuales, generando trazados del centro de Mérida.
El objetivo de Mozilla es mejorar la calidad de los juegos en la Web y está dando un gran paso adelante con el nuevo lanzamiento de Unity; motor de videojuegos multiplataforma desarrollado por Unity Technologies, ahora en su versión Unity 5. Esta nuevaversión de la herramientade desarrollo de juegos y la más popular delmundo incluyeuna vista previa desuincreíbleexportadorWebGL. Con Unity5 losdesarrolladoresestána un clic dela publicación de susjuegos enlaWebde una forma totalmentenueva, aprovechando las ventajas deWebGL y asm.js.
Elresultado es un rendimientosimilar al nativoenlos navegadores de escritoriosin necesidad deplugins.
Una excepcional herramienta
Algunas de las características que hacen de Unity una excepcional herramienta para el desarrollo de Videojuegos.
Pequeño tamaño de descarga.
Bajo uso de memoria y renderizado, similitudes que hacen del contenido generado sea sencillo de portar a la Web.
Es el motor gráfico utilizado en Direct3D, OpenGL (Linux y Mac), OpenGL ES (en Android y iOS), e interfaces propietarias en (Wii).
Se necesitaba un nuevo enfoque en navegadores y finalmente ha llegado
Mozilla y Unity trabajaron juntos para encontrar una manera de traer los contenidos desarrollados en Unity 5 a la Web, utilizando sólo estándares compatibles APIs y JavaScript. Se hace posible el nuevo enfoque de Unity para la entrega en la Web utilizando una combinación de IL2CPP y un compilador cruzado llamado Emscripten. IL2CPP fue desarrollado en Unity Technologies y convierte todas las secuencias de comandos dentro del juego a código C ++.
Este nuevo enfoque tiene ventajas de rendimiento al poder ser portado a múltiples plataformas, incluyendo la Web. La continuación de Unity, utiliza Emscripten para convertir el C ++ resultante a asm.js, un subconjunto de JavaScript que puede ser optimizado para funcionar a velocidades nativas en el navegador. Después, el código se ejecuta en el navegador como cualquier otro contenido Web.
Accede a hardware a través de APIs compatibles estándar como WebGL, IndexedDB y Web Audio. Los resultados de esta colaboración han llegado al punto en que es hora de ponerlo en manos de los desarrolladores.
Vive la experienica Unity 5 exportado usando WebGL 1
Unity tiene una larga historia y un terreno aun desconocido en la Web, pero que sin duda es un paso más a la apertura en la Web.
Andreas Gal – CTO de Mozilla
“Unity siempre ha sido un firme defensor de los juegos web, con la capacidad de hacer la exportación WebGL-plugin gratuito con Unity 5, Mozilla se emociona al ver a Unity promocionarse en la Web como plataforma de primera clase para sus desarrolladores. One-click exportación a WebGL dará a los desarrolladores de Unity la capacidad de compartir su contenido con una nueva clase de usuario “
Firefox OS desencadena el futuro, impulsa la nueva categoría de dispositivos.
En 2014, se anuncio la alianza entre Mozilla y la firma electrónica de Panasonic para desarrollar la Smart TV 4K Ultra HD Life+Screen con Firefox OS. La nueva colaboración es bastante prometedora, ahora la interfaz será más fácil para los usuarios, el acceso a su contenido favorito de manera más rápida, incluyendo TV en directo, aplicaciones, páginas web y contenido en otros dispositivos.
En los televisores Panasonic equipados con Firefox OS, la pantalla permitirá notificaciones de las aplicaciones y, en un futuro, también de los dispositivos compatibles conectados, posibilitará a los desarrolladores crear de manera fácil aplicaciones para smartphones y tablets, así como acceder remotamente al televisor y operarlo.
La firma de electrónica confirmó la disponibilidad de televisores inteligentes 4K con Firefox OS en esta próxima primavera.
Firefox OS es la primera plataforma móvil verdaderamente abierta desarrollado enteramente en tecnologías Web, trayendo más opciones y control para la industria móvil y la entrega de un incomparable nivel de personalización que permite a los desarrolladores, operadores, fabricantes de hardware e incluso los consumidores a crear experiencias personalizadas e innovadoras relacionadas.
Smart TV 4K Ultra HD Life+Screen
+ Pantalla Vida y Firefox OS
Life + de la pantalla y Firefox OS dispositivos de pantalla
Life + de la pantalla y el sistema operativo Firefox Dashboard
Life + de la pantalla y Firefox OS Personalización de la pantalla de inicio
Andreas Gal – CTO Mozilla
“Firefox OS enciende todo, desde teléfonos inteligentes a una nueva categoría de dispositivos como televisores y dispositivos de transmisión, demuestra la flexibilidad y el poder de la Web como la plataforma, estamos muy entusiasmados con la colaboración con Panasonic para ofrecer los primeros televisores integrados con Firefox OS, ya que ofrece al consumidor y los desarrolladores una forma personalizada y fácil de usar para tomar su experiencia web Firefox a través de dispositivos.”
Si es así, Firefox es tu punto de entrada a la Word Wide Web.
Todas las características disponibles de Firefox en escritorio, ahora se encuentran también disponibles para tu dispositivo Android.
Un navegador agradable, más rápido, más inteligente y por supuesto más seguro; ¡claro! con características útiles que hacen que tu experiencia de navegación sea fácil y dinámica.
Firefox está hecho por gente que pone los principios por delante de los beneficios a diferencia de otras organizaciones, creemos firmemente que tus datos te pertenecen, por lo que ofrecemos herramientas que te permiten proteger tu propia información en lugar de recolectarla y venderla de la manera en que otros lo hacen.
En Mozilla hemos sido pioneros y defensores de la Web durante más de 15 años. Nuestro objetivo es la promoción de estándares abiertos que permitan la innovación, fomentando la Web como plataforma para todos.
Hoy por hoy, unos 500 millones de personas utilizan Mozilla Firefox en todo el mundo para acceder a la Web a través de ordenadores, tabletas y dispositivos móviles.
¿Estas listo para llevar a lo más alto tu experiencia de navegación con tu dispositivo Android?
Descarga Firefox para Android.
Características del navegador Firefox:
VELOCIDAD
Accede a la Web y encuentra lo que necesitas rápidamente.
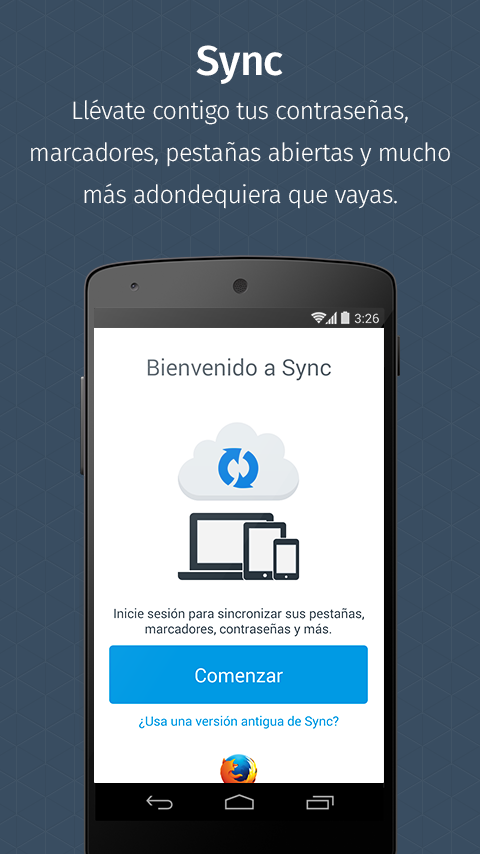
SYNC
Accede al historial, marcadores, contraseñas y pestañas abiertas de tu navegador de escritorio desde cualquier dispositivo.
SEGURIDAD AVANZADA
Controla la privacidad, seguridad y la cantidad de datos que compartes en la Web.
PANTALLA ALUCINANTE
Navega por tus sitios favoritos casi sin usar el teclado.
MODO DE LECTURA
Transforma automáticamente una multitud caótica de artículos e historias en una bonita página fácil de leer.
COMPLEMENTOS
Personaliza tu navegador justo como tú quieres.
Más acerca de Firefox para Android. Descarga, instalación y migración.
Firefox te ofrece más control sobre tu privacidad. La nueva versión de Firefox incluye el botón Olvidar, que elimina tu historial de navegación reciente sin que afecte al resto de tu información.
Cinco minutos
Dos horas
24 horas
El botón Olvidar es muy útil si usas un equipo público y quieres limpiar tu información, o si llegas a un sitio web dudoso y necesitas salir de ahí rápidamente.
En tan solo unos clics, puedes eliminar tu historial e información personal más reciente – Sigue estos sencillos pasos:
1.Lo primero que tienes que hacer es agregar el botón Olvidar a tu barra de herramientas. ¡Solo tienes que hacerlo una vez!
Personalizar
Haz clic en el botón de menú , luego haz clic en la parte inferior del panel. .
Barra de herramientas
Arrastra el botón Olvidar desde el panel Herramientas y características adicionales a tu barra de herramientas o menú y haz clic en:
2.Cuando quieras eliminar tu historial reciente, haz clic en el botón Olvidar que está en tu barra de herramientas.
3.Elige el tiempo que te gustaría olvidar (cinco minutos, dos horas o 24 horas) y haz clic en el botón rojo
Olvidar
4.Firefox eliminará el historial y las cookiesde esa franja de tiempo que has seleccionado, cerrará las pestañas que tengas abiertas y las volverá a abrir en una ventana nueva y limpia.
Firefox OS está disponible en tres continentes con 12 smartphones, a través de 13 operadores en 24 países. Es el único sistema operativo móvil abierto.
Firefox OS
Lo mejor de la web
Firefox OS, te lleva a una experiencia mejorada de navegación. De esta forma, puedes tener el control sobre tu vida digital y obtener lo mejor de la Web sin importar donde estés.
Hecho con la web
Desarrollado completamente con HTML5 y otros estándares web abiertos, Firefox OS está libre de las limitaciones y normas que imponen las plataformas patentadas existentes.
Hecho por Firefox
Durante los últimos 15 años hemos desempeñado un papel decisivo en la innovación y la transformación de la Web para que continúe siendo abierta y accesible para todos. Como resultado de nuestros esfuerzos, hoy en día una quinta parte de toda la actividad de la Web se genera a través de los productos Firefox.
Telefónica también lanzará el dispositivo Alcatel ONETOUCH Fire C en Costa Rica antes de fin de año, completando así la presencia de Firefox OS en Centroamérica.
Telefónica Uruguay agregó tres nuevos dispositivos con Firefox OS a su portafolio: el ZTE Open C, ZTE Open II y Alcatel ONETOUCH Fire C.
Los clientes de Telefónica en Colombia y Perú ahora pueden adquirir los dispositivos ZTE Open II y Alcatel ONETOUCH Fire C.
Antes de que termine el año, Telefónica lanzará por primera vez en Argentina dispositivos con Firefox OS.
Con la adición de Ecuador en los próximos meses, Telefónica completará su oferta Firefox OS a través de todos sus mercados latinoamericanos.
América Móvil, que introdujo teléfonos con Firefox OS en México este año, está comprometida con extender su oferta en América Latina.
Li Gong
“La expansión de Firefox OS en una nueva categoría de smartphones y el continuo crecimiento de nuevos factores representan una gran promesa para la adopción de tecnologías Web abierta y para permitir que millones de personas puedan acceder a la Web”
Encuentra Firefox OS, encuentra un dispositivo en: México
Hace diez años construimos Firefox para mantener el Internet en nuestras manos – crear una elección y poner a las personas en el control de sus vidas “en línea”. Nuestra atención se ha centrado en construir productos que impulsen la competencia, energía e innovación. Necesitamos todos mantener la Web abierta, en todas partes e independiente.
Buscar es parte fundamental de la experiencia en línea para todo el mundo – solo los usuarios de Firefox buscan en la Web más de 100 mil millones de veces por año -.
Con Firefox popularizamos la integración de buscar en el navegador. Nos asociamos con compañías de Internet, incluyendo a Google, Yahoo y otras compañías para dar una mejor experiencia de búsqueda y generan ingresos para avanzar en nuestramisión
Cuando instituimos una opción de búsqueda por default, rompimos el estándar de la industria al rehusarnos términos comerciales que exigían exclusividad. Y a lo largo de los últimos 10 años siempre hemos proporcionado alternativas pre-instaladas, y maneras sencillas para nuestros usuarios de cambiar, añadir o eliminar los motores de búsqueda.
Google ha sido el motor de búsqueda default desde el 2004. El acuerdo llegó el momento de renovar este año, y lo tomamos como una oportunidad para revisar nuestra estrategia de competitividad y explorar nuestras opciones.
Promoviendo la elección y la innovación
Hoy anunciamos un cambio en nuestra estrategia para Firefox con respecto a los motores de búsqueda. Estamos terminando nuestra práctica de tener un único motor de búsqueda predeterminado global. Estamos adoptando un enfoque más local y flexible para aumentar la elección y la innovación en la web, con nuevas y más amplias alianzas de búsqueda por país:
Estados Unidos
Yahoo se convertirá en el motor de búsqueda por default para Firefox en los EE.UU.
Comenzando en Diciembre los usuarios de Firefox serán introducidos en una nueva experiencia del buscador Yahoo mejorado, dentro de las características es que es limpio, con una interfaz moderna que trae lo mejor de la Web.
Bajo esta asociación, Yahoo soportará la opción “No quiero ser rastreado” en Firefox.
Google, Bing, DuckDuckGo, eBay, Amazon, Twitter y Wikipedia continuarán incorporados como buscadores alternativos.
Rusia
El buscador Yandex se convertirá en el buscado por defecto para Firefox en Rusia.
Google, DuckDuckGo, OZON.ru, Price.ru, Mail.ru y Wikipedia continuarán incorporados como buscadores alternativos.
China
Baidu continuará siendo el buscador por defecto para Firefox en China.
Google, Bing, Youdao, Taobao y otras opciones locales continuarán incorporados como buscadores alternativos.
Todos los países
Firefox es un navegador para todo el mundo, independientemente de preferencias de búsqueda.
Ahora Firefox tendrá más opciones en proveedores de búsqueda que cualquier otro buscador. Con 61 proveedores de búsqueda preinstalados en Firefox a través de 88 diferentes idiomas.
Google continuará siendo una opción de búsqueda preinstalada .
Google también continuará proveyendo las características de navegación segura y geolocalización de Firefox
El año 1998 quedo atrás, pero fue el año que marco la historia de Internet y de Mozilla, organización preocupada por el uso de estándares abiertos y que lucha por mantener una web abierta, y donde un puñado de gente apasionada dio al mundo algo diferente, una alternativa para poder navegar en internet llamada, Firefox, un navegador el cual su código se encuentra disponible en la red ya que es software libre. Su lanzamiento oficial fue el invierno de noviembre de 2004.
Muchos nombres han pasado: Phoenix, Firebirb, Firebird Browser, Mozilla Firebirb para finalmente pasar a estar escrito en el filo de la eternidad como Mozilla Firefox ®
Hoy, Firefox sigue y seguirá siendo el único navegador que no responde a intereses corporativos, no responde a la industria y lo más importante, sin fines de lucro, creemos en Internet donde el poder está en tus manos.
Somos una organización no lucrativa global dedicada a mantener la web segura y accesible en todas partes. Contamos con miles de voluntarios de todo el mundo que ayuden a construir Firefox y otras sorprendentes, tecnologías innovadoras.
Grandes cambios han pasado desde hace 10 años, por ello y con una mirada al futuro ¡Felices 10 años Mozilla Firefox!
En Mozilla sabemos que los desarrolladores son parte fundamental de la web, es por ello que continuamente estamos impulsando estándares y creando herramientas que faciliten la creación de contenido web y apps asombrosas.
Cuando construimos la web, los desarrolladores utilizamos varias herramientas que normalmente no funcionan bien entre sí. Esto significa estar moviéndonos entre diferentes herramientas, plataformas y navegadores haciendo el proceso más lento y menos productivo.
Así que le dimos rienda suelta al equipo de herramientas para desarrolladores en todo el navegador para ver de qué forma podían hacer la vida más facil a los desarrolladores.
Ahora estamos listos para darles un adelanto del
primer navegador enfocado a los desarrolladores.
Hemos rediseñado el navegador con un nuevo enfoque, colocando los intereses del desarrollador en primer plano. Está construido por desarrolladores para desarrolladores, para que puedan depurar toda la web y construir de manera más fácil maravillosas experiencias web. También integra nuevas y potentes herramientas como WebIDE y el Firefox Tool Adapter.
Prepárate para correr la voz (#FX10) o suscríbete a nuestro boletín de noticias de Hack aquí para recibir un correo tan pronto el navegador esté disponible.
Estamos ansiosos de compartirlo con ustedes este 10 de Noviembre.
¡Celebra con nosotros los 10 años de Firefox! 10 años en los que hemos marcando la diferencia a través de la promoción de la apertura y oportunidades igualitarias en la Web.
Desde aquel lejano 9 de noviembre del 2004 que Firefox 1.0 vio la luz, pasando por el anuncio de 2 páginas en el New York Times anunciando el lanzamiento de Firefox que mas de 10,000 Mozillians hicieron posible hasta el record Guinness que logramos al lograr que 8,002,530 personas escogieran descargar firefox 3 en el 2008.
Estamos muy felices de cumplir nuestros primeros 10 años, te invitamos a celebrar con nosotros. Es muy sencillo:
Tomate una foto de ti en un lugar icónico con un cartel que diga: “Firefox es mi elección independiente en [País o región]” con los hashtags: #Chooseindependent y #FX10












 , luego haz clic en la parte inferior del panel. .
, luego haz clic en la parte inferior del panel. .
 desde el panel Herramientas y características adicionales a tu barra de herramientas o menú y haz clic en:
desde el panel Herramientas y características adicionales a tu barra de herramientas o menú y haz clic en: 





